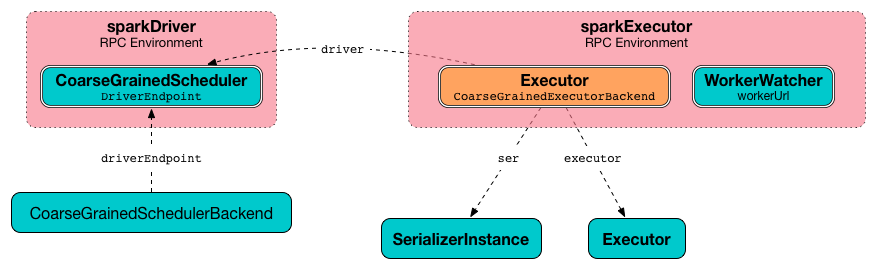
CoarseGrainedExecutorBackend
CoarseGrainedExecutorBackend is an ExecutorBackend to manage a single coarse-grained executor (that lives as long as the owning executor backend).
CoarseGrainedExecutorBackend registers itself as a ThreadSafeRpcEndpoint under the name Executor to communicate with the driver.
|
Note
|
The internal executor reference is created after a connection to the driver is established. |
Figure 1. CoarseGrainedExecutorBackend and Others
When launched, CoarseGrainedExecutorBackend immediately connects to the owning CoarseGrainedSchedulerBackend to inform that it can run tasks. It is launched as a command-line application by:
-
Spark Standalone’s StandaloneSchedulerBackend
-
Spark on YARN’s ExecutorRunnable
-
Spark on Mesos’s MesosCoarseGrainedSchedulerBackend.
When it cannot connect to driverUrl, it terminates (with the exit code 1).
|
Caution
|
What are SPARK_LOG_URL_ env vars? Who sets them?
|
When the driver terminates, CoarseGrainedExecutorBackend exits (with exit code 1).
ERROR Driver [remoteAddress] disassociated! Shutting down.All task status updates are sent along to driverRef as StatusUpdate messages.
|
Tip
|
Enable Add the following line to |
Extracting Log URLs — extractLogUrls Method
|
Caution
|
FIXME |
Creating CoarseGrainedExecutorBackend Instance
CoarseGrainedExecutorBackend(
override val rpcEnv: RpcEnv,
driverUrl: String,
executorId: String,
hostname: String,
cores: Int,
userClassPath: Seq[URL],
env: SparkEnv)
extends ThreadSafeRpcEndpoint with ExecutorBackendWhile being created, CoarseGrainedExecutorBackend initializes the internal properties (e.g. executor and driver) and creates a SerializerInstance (using SparkEnv.closureSerializer).
|
Note
|
CoarseGrainedExecutorBackend is created when…FIXME
|
Starting RpcEndpoint — onStart Method
|
Note
|
onStart is a RpcEndpoint callback method that is executed before a RPC endpoint starts to handle messages.
|
When executed, you should see the following INFO message in the logs:
INFO CoarseGrainedExecutorBackend: Connecting to driver: [driverUrl]It then retrieves the RpcEndpointRef of the driver asynchronously (using the constructor’s driverUrl) and initializes the internal driver property that it will send a blocking RegisterExecutor message to.
If there is an issue while registering the executor, you should see the following ERROR message in the logs and process exits (with the exit code 1).
ERROR Cannot register with driver: [driverUrl]|
Note
|
The RegisterExecutor message contains executorId, the RpcEndpointRef to itself, cores, and log URLs of the CoarseGrainedExecutorBackend.
|
driver RpcEndpointRef
driver is an optional RpcEndpointRef for the driver.
|
Tip
|
See Starting RpcEndpoint — onStart Method for how driver is initialized.
|
Driver’s URL
The driver’s URL is of the format spark://[RpcEndpoint name]@[hostname]:[port], e.g. spark://CoarseGrainedScheduler@192.168.1.6:64859.
Launching CoarseGrainedExecutorBackend As Standalone Application — main Method
CoarseGrainedExecutorBackend is a command-line application (it comes with main method).
It accepts the following options:
-
--driver-url(required) - the driver’s URL. See driver’s URL.
-
--executor-id(required) - the executor’s id -
--hostname(required) - the name of the host -
--cores(required) - the number of cores (must be greater than0) -
--app-id(required) - the id of the application -
--worker-url- the worker’s URL, e.g.spark://Worker@192.168.1.6:64557 -
--user-class-path- a URL/path to a resource to be added to CLASSPATH; can be specified multiple times.
Unrecognized options or required options missing cause displaying usage help and exit.
$ ./bin/spark-class org.apache.spark.executor.CoarseGrainedExecutorBackend
Usage: CoarseGrainedExecutorBackend [options]
Options are:
--driver-url <driverUrl>
--executor-id <executorId>
--hostname <hostname>
--cores <cores>
--app-id <appid>
--worker-url <workerUrl>
--user-class-path <url>It first fetches Spark properties from CoarseGrainedSchedulerBackend (using the driverPropsFetcher RPC Environment and the endpoint reference given in driver’s URL).
For this, it creates SparkConf, reads spark.executor.port setting (defaults to 0) and creates the driverPropsFetcher RPC Environment in client mode. The RPC environment is used to resolve the driver’s endpoint to post RetrieveSparkProps message.
It sends a (blocking) RetrieveSparkProps message to the driver (using the value for driverUrl command-line option). When the response (the driver’s SparkConf) arrives it adds spark.app.id (using the value for appid command-line option) and creates a brand new SparkConf.
If spark.yarn.credentials.file is set, …FIXME
A SparkEnv is created using SparkEnv.createExecutorEnv (with isLocal being false).
|
Caution
|
FIXME |
Setting Up Executor RPC Endpoint (and WorkerWatcher Perhaps) — run Internal Method
run(driverUrl: String,
executorId: String,
hostname: String,
cores: Int,
appId: String,
workerUrl: Option[String],
userClassPath: scala.Seq[URL]): Unitrun requests the driver for the Spark properties and sets up the Executor RPC endpoint (with CoarseGrainedExecutorBackend as the RPC endpoint) and optionally the WorkerWatcher RPC endpoint. It keeps running (yet the main thread is blocked and only the RPC endpoints process RPC messages) until the RpcEnv terminates.
When executed, you should see the following INFO message in the logs:
INFO Started daemon with process name: [processName]run then runs in a secured environment as a Spark user.
run first creates a brand new SparkConf to get spark.executor.port from. It then creates a RpcEnv called driverPropsFetcher.
|
Note
|
The host name and port for the driverPropsFetcher RpcEnv are given as the input argument hostname and got from SparkConf, respectively.
|
|
Caution
|
FIXME What’s clientMode in RpcEnv.create?
|
run uses the driverPropsFetcher RpcEnv to request driverUrl endpoint for the Spark properties to use only. The Spark properties are extended with spark.app.id Spark property with the value of appId.
run uses the Spark properties to create a SparkEnv for the executor (with isLocal disabled).
|
Note
|
executorId, hostname, and cores to create the SparkEnv are the input arguments of run.
|
|
Caution
|
FIXME Describe spark.yarn.credentials.file.
|
After the SparkEnv has been created, run sets up the endpoint under the name Executor with CoarseGrainedExecutorBackend as the RPC endpoint.
If the optional workerUrl is specified, run sets up another endpoint under the name WorkerWatcher and WorkerWatcher RPC endpoint.
|
Caution
|
FIXME When is workerUrl specified?
|
run's thread is blocked until RpcEnv terminates (and so the other threads of the RPC endpoints could run).
Once RpcEnv has terminated, run stops the thread for credential updates.
|
Caution
|
FIXME Think of the place for Utils.initDaemon, Utils.getProcessName et al.
|
|
Note
|
run is executed when CoarseGrainedExecutorBackend command-line application is launched.
|
executor Internal Property
executor is the internal reference to a coarse-grained executor…FIXME
|
Caution
|
FIXME |
RPC Messages
RegisteredExecutor
RegisteredExecutor
extends CoarseGrainedClusterMessage with RegisterExecutorResponseWhen a RegisteredExecutor message arrives, you should see the following INFO in the logs:
INFO CoarseGrainedExecutorBackend: Successfully registered with driverThe internal executor is created (passing in the constructor’s parameters) with isLocal disabled.
|
Note
|
RegisteredExecutor is sent when CoarseGrainedSchedulerBackend is notified about a new executor.
|
RegisterExecutorFailed
RegisterExecutorFailed(message)When a RegisterExecutorFailed message arrives, the following ERROR is printed out to the logs:
ERROR CoarseGrainedExecutorBackend: Slave registration failed: [message]CoarseGrainedExecutorBackend then exits with the exit code 1.
LaunchTask
LaunchTask(data: SerializableBuffer)The LaunchTask handler deserializes TaskDescription from data (using the global closure Serializer).
|
Note
|
LaunchTask message is sent by CoarseGrainedSchedulerBackend.launchTasks.
|
INFO CoarseGrainedExecutorBackend: Got assigned task [taskId]It then launches the task on the executor (using Executor.launchTask method).
If however the internal executor field has not been created yet, it prints out the following ERROR to the logs:
ERROR CoarseGrainedExecutorBackend: Received LaunchTask command but executor was nullAnd it then exits.
KillTask
KillTask(taskId, _, interruptThread) message kills a task (calls Executor.killTask).
If an executor has not been initialized yet (FIXME: why?), the following ERROR message is printed out to the logs and CoarseGrainedExecutorBackend exits:
ERROR Received KillTask command but executor was nullStopExecutor
StopExecutor message handler is receive-reply and blocking. When received, the handler prints the following INFO message to the logs:
INFO CoarseGrainedExecutorBackend: Driver commanded a shutdownIt then sends a Shutdown message to itself.
Shutdown
Shutdown stops the executor, itself and RPC Environment.